Paket Python Terbaik yang Harus Diketahui di Tahun 2024
- Cornellius Yudha Wijaya
- 12 Jul 2024
- 5 menit membaca
Diperbarui: 16 Jul 2024

Tahun lalu adalah tahun yang luar biasa bagi siapa pun yang berkecimpung di dunia data, terutama bagi mereka yang menggunakan Python, karena ada banyak paket menarik yang meningkatkan kemampuan data kita.
Menghadapi tahun ini, berbagai paket Python akan meningkatkan workflow data kita di tahun baru ini. Apa saja paket-paket tersebut? Mari kita lihat rekomendasi saya.
Dari paket data cleaning hingga implementasi machine learning, berikut adalah paket data Python terbaik yang perlu Anda ketahui di tahun 2024.
1. Pyjanitor
Pyjanitor adalah paket Python open-source yang dikembangkan khusus untuk rutinitas data cleaning melalui method chaining dan dirancang untuk meningkatkan API Pandas untuk data cleaning.
Kita tahu banyak metode Pandas untuk data cleaning, seperti dropna untuk menghapus semua missing value. Dengan Pyjanitor, proses data cleaning dengan API Pandas akan ditingkatkan dengan memperkenalkan metode tambahan dalam API tersebut. Bagaimana cara kerjanya? Mari kita coba paket ini dengan data sampel.
Kita akan menggunakan data Titanic dari Kaggle yang dilisensikan di bawah CC0: Public Domain for the sample. Mari mulai dengan menginstal paket Pyjanitor.
Instalasi
pip install pyjanitorMari kita lihat dataset kita saat ini sebelum melakukan data cleaning dengan Pyjanitor.
import pandas as pd
df = pd.read_csv('train.csv')
df.head()Output

Dengan paket Pyjanitor, kita bisa melakukan berbagai data cleaning tambahan dan menerapkan method chains dalam cara kerja API Pandas.
Mari kita lihat bagaimana paket ini bekerja dengan kode di bawah ini.
Contoh Kode
import janitor
df.remove_columns(["Cabin"]).expand_column(column_name = 'Embarked').clean_names()Output

Dengan mengimpor paket Pyjanitor, maka akan otomatis diterapkan dalam Pandas DataFrame. Pada kode di atas, kita telah melakukan hal-hal berikut menggunakan Pyjanitor:
Menghapus kolom ‘Cabin’ menggunakan metode remove_columns,
Categorical Encoding (One-Hot Encoding) pada kolom Embarked menggunakan metode expand_column,
Mengubah semua nama variabel menjadi huruf kecil, dan jika ada spasi akan diganti dengan garis bawah menggunakan metode clean_names.
Masih banyak fungsi lain di Pyjanitor yang bisa kita gunakan untuk data cleaning. Silakan merujuk ke dokumentasi mereka untuk daftar API lengkapnya.
2. Pingouin
Pingouin adalah paket Python open-source untuk analisis statistik yang sering digunakan untuk aktivitas statistik oleh data scientist. Paket ini dirancang untuk kesederhanaan dengan menyediakan kode satu baris tetapi tetap menyediakan berbagai uji statistik yang dapat digunakan.
Instalasi
pip install pingouinSetelah menginstal paket ini, mari kita coba melakukan analisis statistik dengan Pingouin. Sebagai contoh, kita akan melakukan uji T dan uji ANOVA menggunakan dataset Titanic sebelumnya.
Contoh Kode
import pingouin as pg
#T-Test
print('T-Test example')
pg.ttest( df['Age'], df['Fare'])
print('\n')
# ANOVA test
print('ANOVA test example')
pg.anova(data=df, dv='Age', between='SibSp', detailed=True)Output

Dengan satu baris kode, Pingouin menyediakan hasil uji statistik dalam objek data frame. Ada banyak fungsi lain untuk membantu analisis kita, yang dapat kita eksplorasi di dokumentasi API Pingouin.
3. PyCaret
PyCaret adalah paket Python open-source yang dikembangkan untuk mengotomatisasi machine learning workflow. Paket ini menyediakan lingkungan low-code untuk mempercepat eksperimen model dengan menyediakan alat model machine learning end-to-end.
Umumnya dalam pekerjaan data science terdapat banyak aktivitas, seperti data cleaning, memilih model, melakukan penyetelan hyperparameter, dan mengevaluasi model. PyCaret bertujuan untuk menghilangkan semua kerumitan tersebut dengan meminimalkan semua kode yang diperlukan menjadi sesedikit mungkin.
Paket ini adalah kumpulan dari beberapa kerangka kerja machine learning menjadi satu. Mari kita coba PyCaret untuk mengetahui lebih lanjut.
Instalasi
pip install pycaretMenggunakan dataset Titanic sebelumnya; kita akan mengembangkan model classifier untuk memprediksi variabel Survive.
Contoh Kode
from pycaret.classification import *
clf_exp = setup(data = df, target = 'Survived') Output
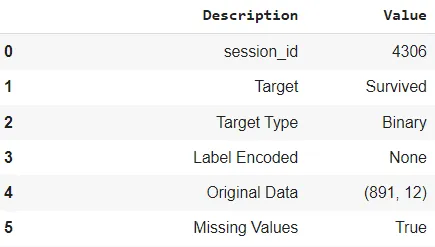
Pada kode di atas, kita memulai eksperimen menggunakan fungsi setup. Dengan memberikan data dan target, PyCaret akan menyimpulkan data kita dan mengembangkan model machine learning berdasarkan data yang diberikan. Informasi output sebenarnya lebih panjang daripada gambar di atas dan memberikan wawasan tentang apa yang terjadi dalam proses pemodelan kita.
Mari kita lihat hasil model dan menginfer model terbaik dari data pelatihan.
best_model = compare_models(sort = 'precision')
print(best_model)Output

Eksperimen classifier PyCaret akan menguji data pelatihan ke dalam 14 classifier berbeda dan memberikan model terbaik. Dalam kasus kita, itu adalah RidgeClassifier.
Masih banyak eksperimen yang bisa Anda lakukan dengan PyCaret. Untuk eksplorasi lebih lanjut, silakan merujuk ke dokumentasi mereka.
4. BentoML
BentoML adalah paket Python open source untuk dengan cepat menyiapkan model ke dalam produksi dengan beberapa baris kode saja. Paket ini bertujuan untuk fokus pada model machine learning yang diproduksi agar mudah digunakan oleh pengguna.
Mari kita coba paket BentoML dan pelajari cara kerjanya.
Instalasi
pip install bentomlSebagai contoh BentoML, kita akan menggunakan kode dari tutorial paket dengan sedikit modifikasi.
Contoh Kode
Kita akan melatih model classifier menggunakan dataset iris.
from sklearn import svm, datasets
iris = datasets.load_iris()
X, y = iris.data, iris.target
iris_clf = svm.SVC()
iris_clf.fit(X, y)Dengan BentoML, kita bisa menyimpan model machine learning kita di penyimpanan lokal atau cloud dan mengambilnya untuk produksi.
import bentoml
bentoml.sklearn.save_model("iris_clf", iris_clf)Kemudian kita bisa menggunakan model yang disimpan dalam lingkungan BentoML menggunakan instance runner.
# Create a Runner instance and implement a runner instance in local
iris_clf_runner = bentoml.sklearn.get("iris_clf:latest").to_runner()
iris_clf_runner.init_local()
# Using the predictor on unseen data
iris_clf_runner.predict.run([[4.1, 2.3, 5.5, 1.8]])Output
array([2])Selanjutnya, kita bisa memulai layanan model yang disimpan di BentoML dengan menjalankan kode berikut untuk membuat file Python dan memulai server.
%%writefile service.py
import numpy as np
import bentoml
from bentoml.io import NumpyNdarray
iris_clf_runner = bentoml.sklearn.get("iris_clf:latest").to_runner()
svc = bentoml.Service("iris_clf_service", runners=[iris_clf_runner])
@svc.api(input=NumpyNdarray(), output=NumpyNdarray())
def classify(input_series: np.ndarray) -> np.ndarray:
return iris_clf_runner.predict.run(input_series)Kita memulai server dengan menjalankan kode di bawah ini.
!bentoml serve service.py:svc --reloadOutput

Output akan menunjukkan log server pengembangan saat ini dan di mana kita bisa mengaksesnya. Jika kita puas dengan hasil pengembangan, kita bisa melanjutkan ke produksi. Saya merekomendasikan Anda merujuk ke dokumentasi untuk proses produksi.
5. Streamlit
Streamlit adalah paket Python open source untuk membuat aplikasi web khusus untuk data scientist. Paket ini menyediakan kode yang mudah dipahami untuk membangun dan menyesuaikan berbagai aplikasi data. Mari kita coba paket ini untuk mempelajari cara kerjanya.
Instalasi
pip install streamlitAplikasi web Streamlit dijalankan dengan mengeksekusi skrip Python menggunakan streamlit. Oleh karena itu, kita perlu menyiapkan skrip sebelum menjalankannya menggunakan perintah streamlit.
Kita bisa menjalankan contoh berikut menggunakan IDE favorit Anda atau Jupyter Notebook, tetapi saya akan menunjukkan cara kita membuat aplikasi web dengan Streamlit di Jupyter Notebook.
Contoh Kode
%%writefile streamlit_example.py
import streamlit as st
import pandas as pd
import numpy as np
st.title('Titanic Data')
data = pd.read_csv('train.csv')
st.write('Shows top 5 of the data')
st.dataframe(data.head())
st.title('Bar Chart Visualization with Age')
col = st.selectbox('Select the categorical columns', data.select_dtypes('object').columns)
st.bar_chart(data, x = col, y='Age')Kode di atas akan membuat skrip yang disebut streamlit_example.py dan membuat aplikasi web yang mirip dengan output di bawah ini jika kita menjalankan perintah Streamlit.
!streamlit run streamlit_example.py
Kodenya mudah dipelajari dan tidak akan memakan waktu lama bagi Anda untuk membuat aplikasi web dengan Streamlit. Anda bisa merujuk ke dokumentasinya jika ingin mengetahui lebih lanjut tentang apa yang bisa Anda buat dengan paket Streamlit.
Kesimpulan
Menghadapi tahun ini, kita harus meningkatkan keterampilan data menjadi lebih baik daripada tahun sebelumnya. Apa cara yang lebih baik untuk menambah senjata data kita daripada belajar dari paket Python yang luar biasa yang akan membantu meningkatkan workflow data kita.
Paket Python terbaik ini adalah:
Pyjanitor
Pingouin
PyCaret
BentoML
Streamlit
Commentaires