Proyek RedPajama: Inisiatif Open-Source untuk Mendemokratisasi LLM
- Cornellius Yudha Wijaya
- 21 Jul 2024
- 3 menit membaca

Akhir-akhir ini, Large Language Models atau LLM telah mendominasi dunia. Dengan diperkenalkannya ChatGPT, sekarang semua orang dapat memanfaatkan model pembuatan teks. Namun, banyak model canggih hanya tersedia secara komersial, meninggalkan banyak penelitian hebat dan kustomisasi di belakangnya.
Tentu saja, saat ini ada banyak proyek yang mencoba menjadikan banyak LLM sebagai open-source sepenuhnya. Proyek seperti Pythia, Dolly, DLite, dan banyak lainnya adalah beberapa contohnya. Tapi mengapa mencoba menjadikan LLM open-source? Sentimen komunitaslah yang menggerakkan semua proyek ini untuk menjembatani keterbatasan yang ditimbulkan oleh model tertutup. Namun, apakah model open-source lebih inferior dibandingkan dengan yang tertutup? Tentu saja tidak. Banyak model yang dapat menyaingi model komersial dan menunjukkan hasil yang menjanjikan di banyak bidang.
Untuk mengikuti gerakan ini, salah satu proyek open-source untuk mendemokratisasi LLM adalah RedPajama. Apa proyek ini, dan apa manfaatnya bagi komunitas? Mari kita jelajahi lebih lanjut.
RedPajama
RedPajama adalah proyek kolaborasi antara Ontocord.ai, ETH DS3Lab, Stanford CRFM, dan Hazy Research untuk mengembangkan LLM open-source yang dapat direproduksi. Proyek RedPajama memiliki tiga tonggak pencapaian, termasuk:
Pre-training data
Base models
Instruction tuning data and models
Saat artikel ini ditulis, proyek RedPajama telah mengembangkan pre-training data dan model, termasuk versi base, instructed, dan chat.
RedPajama Pre-Trained Data
Pada langkah pertama, RedPajama mencoba mereplikasi dataset model semi-open LLaMa. Ini berarti RedPajama mencoba membangun pre-trained data dengan 1,2 triliun token dan fully open-source untuk komunitas. Saat ini, data lengkap dan sampel data dapat diunduh di HuggingFace.
Sumber data untuk dataset RedPajama dirangkum dalam tabel di bawah ini.
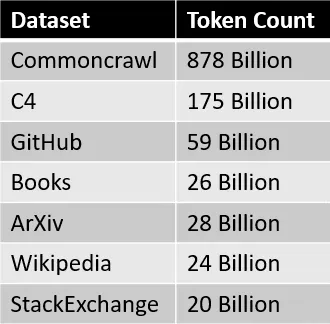
Setiap bagian data diproses dan disaring dengan hati-hati, jumlah tokennya juga kira-kira sesuai dengan yang dilaporkan dalam paper LLaMa
.
Langkah berikutnya setelah pembuatan dataset adalah pengembangan base model.
Model RedPajama
Beberapa minggu setelah pembuatan dataset RedPajama, model pertama yang dilatih pada dataset tersebut dirilis. Base Model memiliki dua versi: model dengan 3 miliar dan 7 miliar parameter. Proyek RedPajama juga merilis dua variasi dari setiap model dasar: instruction-tuned dan chat model.
Ringkasan setiap model dapat dilihat pada tabel di bawah ini.

Anda dapat mengakses model-model di atas menggunakan tautan berikut:
Mari kita coba Base Model RedPajama. Misalnya, kita akan mencoba base model RedPajama 3B dengan kode yang diadaptasi dari HuggingFace.
import torch
import transformers
from transformers import AutoTokenizer, AutoModelForCausalLM
# init
tokenizer = AutoTokenizer.from_pretrained(
"togethercomputer/RedPajama-INCITE-Base-3B-v1"
)
model = AutoModelForCausalLM.from_pretrained(
"togethercomputer/RedPajama-INCITE-Base-3B-v1", torch_dtype=torch.bfloat16
)
# infer
prompt = "Mother Teresa is"
inputs = tokenizer(prompt, return_tensors="pt").to(model.device)
input_length = inputs.input_ids.shape[1]
outputs = model.generate(
**inputs,
max_new_tokens=128,
do_sample=True,
temperature=0.7,
top_p=0.7,
top_k=50,
return_dict_in_generate=True
)
token = outputs.sequences[0, input_length:]
output_str = tokenizer.decode(token)
print(output_str)a Catholic saint and is known for her work with the poor and dying in Calcutta, India.
Born in Skopje, Macedonia, in 1910, she was the youngest of thirteen children. Her parents died when she was only eight years old, and she was raised by her older brother, who was a priest.
In 1928, she entered the Order of the Sisters of Loreto in Ireland. She became a teacher and then a nun, and she devoted herself to caring for the poor and sick.
She was known for her work with the poor and dying in Calcutta, India.Hasil base model 3B menjanjikan, dan mungkin lebih baik jika kita menggunakan base model 7B. Karena pengembangan masih berlangsung, proyek ini mungkin akan memiliki model yang lebih baik di masa depan.
Kesimpulan
AI Generatif sedang meningkat, tetapi sayangnya banyak model hebat masih terkunci di bawah arsip perusahaan. RedPajama adalah salah satu proyek terdepan yang mencoba mereplikasi model semi-open LLaMA untuk mendemokratisasi LLM.
Dengan mengembangkan dataset yang mirip dengan LLaMA, RedPajama berhasil menciptakan dataset open-source dengan 1,2 triliun token yang telah digunakan oleh banyak proyek open-source.
RedPajama juga merilis dua jenis model; base model dengan parameter 3B dan 7B, di mana setiap base model berisi instruction-tuned dan chat model.
Comments