Pengembangan End-to-End Machine Learning Project: Spam Classifier
- Cornellius Yudha Wijaya
- 13 Jul 2024
- 16 menit membaca
Diperbarui: 16 Jul 2024

Semua kode yang digunakan dalam artikel ini disimpan dalam repositori end-to-end spam classifier. Sebaiknya kloning repositori untuk mengikuti pembelajaran pada artikel ini.
Jika kita mengatakan bahwa proyek end-to-end machine learning tidak berhenti ketika dikembangkan, itu hanya setengah jalan.
Proyek machine learning dikatakan berhasil jika model tersebut telah memasuki production dan menciptakan nilai yang berkelanjutan bagi bisnis.
Banyak pemula pada data science dan machine learning hanya fokus pada proses analisis data dan pengembangan model, yang mana ini dapat dimengerti, karena proses lainnya sering dilakukan oleh departemen lain. Namun, membuat proyek end-to-end machine learning sekarang telah menjadi keharusan.
Dalam artikel ini, saya akan memberikan panduan untuk Anda membuat proyek machine learning spam classifier (Pengklasifikasi Spam) sederhana secara end-to-end. Kita akan melewati semuanya bersama, mulai dari analisis data hingga retraining otomatis. Secara keseluruhan, struktur artikel seperti yang ditunjukkan di bawah ini.
1. Membangun Proyek Data Science
2. Pengembangan Klasifikasi Spam
- EDA dan Pengembangan Model
- Pengembangan Model dan Pelacakan Eksperimen dengan MLFlow
3. Pengembangan Model dengan FastAPI dan Docker
- Back-end Pengklasifikasi Spam
- Bagian Depan Pengklasifikasi Spam
- Menggabungkan Back-end dan Front-end dengan Docker Compose
4. Deteksi Data Drift dan Pemicu Retraining Model
- Deteksi Data Drift dengan AI Terbukti
- Skrip Retraining Model
- Airflow untuk Model Retraining
5. KesimpulanJadi, mari kita mulai.
Membangun Proyek Data Science
Artikel ini bertujuan untuk mengembangkan proyek data science yang mengikuti struktur end-to-end. Secara umum, struktur keseluruhan proyek kita akan mengikuti diagram di bawah ini.

Anda tidak perlu memahami semua tentang konsep dan alat yang akan kita gunakan, karena saya akan mencoba menjelaskan semuanya secara ringkas namun intuitif.
Dengan pemikiran itu, kita sekarang akan membuat proyek end-to-end data science end-to-end kita.
Pengembangan Klasifikasi Spam
Dalam artikel ini, kita akan mengembangkan model klasifikasi spam sederhana yang memberikan keluaran probabilitas apakah email itu spam. Untuk proyek ini, kita akan menggunakan data mentah yang telah saya simpan di repositori GitHub di sini.
EDA dan Pengembangan Model
Pertama, mari kita lihat datanya dan menjelajahinya.
# Import paket yang dibutuhkan
import pandas as pd
import seaborn as sns
import numpy as np
import matplotlib.pyplot as plt
import warnings
warnings.filterwarnings('ignore')
df = pd.read_csv('spam_emails.csv')
df.head()
Data terdiri dari kolom email dan spam. Kolom email berisi konten email, sedangkan kolom spam memberikan informasi apakah email itu spam atau tidak.
Proyek ini bertujuan untuk mengembangkan model klasifikasi machine learning untuk mengklasifikasikan apakah email tersebut adalah spam atau bukan. Oleh karena itu, kita akan menjelajahi data untuk melihat pola dalam email-email ini.
Mari kita coba melakukan feature engineering pada dataset.
#Memeriksa jumlah kata dan panjang karakter email
df['text_length'] = df['email'].apply(len)
df['email_words'] = df['email'].str.split().apply(len)
Kita akan mengambil panjang teks dan jumlah kata untuk setiap email dari feature engineering di atas. Melihat data, saya menyadari bahwa email mungkin telah diproses sebelumnya, tetapi saya tidak yakin sampai sejauh mana. Saya hanya yakin tentang kasus lower casing, dan saya berasumsi bahwa sampel data mewakili populasi.
Mari kita coba memvisualisasikan panjang teks dan jumlah kata yang berhubungan dengan spam.
# Menggunakan Seaborn untuk melihat perbedaan antara spam dan non-spam berdasarkan jumlah kata.
sns.histplot(df[df['spam'] ==0]['email_words'], color='blue', label='Non-Spam', kde=False, log_scale = True)
sns.histplot(df[df['spam'] ==1]['email_words'], color='orange', label='Spam', kde=False, log_scale = True)
plt.xlabel('Length of Email')
plt.ylabel('Number of Emails')
plt.title('Distribution of Email Words for Spam and Non-Spam Emails')
plt.legend()
# Menggunakan Seaborn untuk melihat perbedaan antara spam dan non-spam berdasarkan panjang kata.
sns.histplot(df[df['spam'] ==0]['text_length'], color='blue', label='Non-Spam', kde=False, log_scale = True)
sns.histplot(df[df['spam'] ==1]['text_length'], color='orange', label='Spam', kde=False, log_scale = True)
plt.xlabel('Length of Email')
plt.ylabel('Number of Emails')
plt.title('Distribution of Words Length for Spam and Non-Spam Emails')
plt.legend()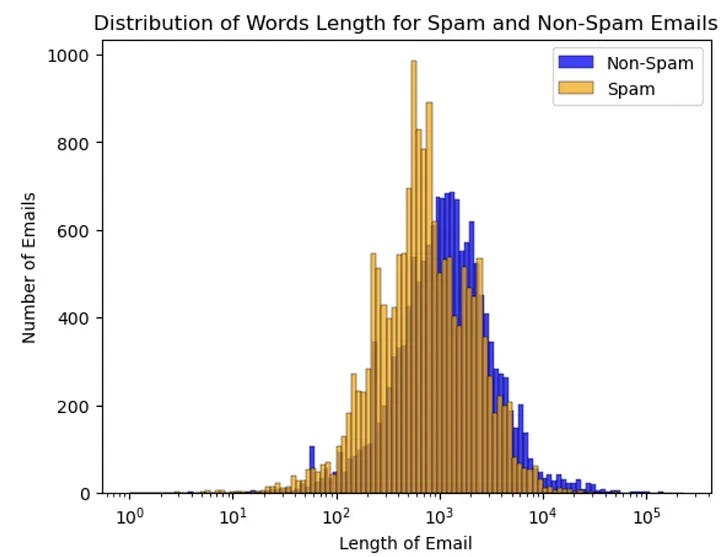
Seperti yang kita lihat, email spam memiliki jumlah kata yang lebih panjang dibandingkan dengan email non-spam. Ini mungkin karena sifat email spam yang ingin meyakinkan penerima bahwa email mereka bukan spam.
Secara keseluruhan, ada perbedaan pola statistik antara email spam dan non-spam.
Pengembangan Model dan Pelacakan Eksperimen dengan MLFlow
Untuk mempercepat proses, mari kita lanjutkan ke pengembangan model klasifikasi spam. Pada bagian ini, kita ingin bereksperimen dengan berbagai metodologi dan model untuk melihat model terbaik.
Namun, kita juga ingin melacak proses dan hasil eksperimen. Di sinilah Pelacakan Eksperimen MLFlow (MLFlow Experiment Tracking) berperan. Kita dapat mencatat dan melacak seluruh proses eksperimen dengan memanfaatkan alat ini.
Sebagai contoh, kita akan mencatat seluruh proses pelatihan. Kita akan mencatat semuanya dari metrik, model, dan dataset yang digunakan untuk eksperimen. Saya tidak akan mencatat parameter karena dapat memakan waktu lebih lama jika kita ingin bereksperimen dengan semua hyperparameter.
Untuk memulainya, kita perlu menginstal paket MLFlow. Kita bisa melakukannya dengan kode berikut.
pip install mlflowKita akan menggunakan server lokal untuk mencatat eksperimen. Ada cara untuk menyimpannya di cloud environment, tetapi mari kita merujuk ke cara lokal.
Jalankan perintah berikut ke CLI untuk memastikan kita dapat memulai server lokal.
mlflow ui
Jika berfungsi dengan baik, Anda akan melihat dashboard seperti gambar di atas di localhost (secara default, ini berada di http://127.0.0.1:5000).
Mari persiapkan proses eksperimen. Untuk melakukannya, kita akan membagi dataset untuk dataset training dan testing.
# Membagi dataset menjadi data training and testing.
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(df.drop('spam', axis =1), df['spam'], test_size = 0.2, stratify = df['spam'], random_state = 42)Kemudian, kita akan menyiapkan eksperimen MLFlow. Kita dapat memulai pembuatan eksperimen dengan kode berikut.
import mlflow
EXPERIMENT_NAME = "NLP-Spam-Classifier-Experiment"
EXPERIMENT_ID = mlflow.create_experiment(EXPERIMENT_NAME)Jika Anda perlu mengakses eksperimen ini sekali lagi, kita dapat melakukannya dengan kode saat ini:
current_experiment=dict(mlflow.get_experiment_by_name(EXPERIMENT_NAME))
experiment_id=current_experiment['experiment_id']Jika semuanya berjalan dengan baik, saya akan menyiapkan kode yang akan menyiapkan eksperimen yang akan terdiri dari beberapa run. Dalam setiap run, akan mencoba beberapa model dengan vektorisasi yang berbeda. Fungsi ini ditunjukkan dalam kode di bawah ini.
import mlflow.data
from mlflow.data.pandas_dataset import PandasDataset
from sklearn.model_selection import cross_validate
from sklearn.feature_extraction.text import CountVectorizer, TfidfVectorizer
from sklearn.metrics import make_scorer, accuracy_score, precision_score, recall_score, f1_score
from sklearn.naive_bayes import MultinomialNB
from sklearn.linear_model import LogisticRegression
from sklearn.ensemble import RandomForestClassifier
from xgboost import XGBClassifier
def evaluate_models(train_data, train_labels, experiment_id):
training_df = pd.concat([X_train['email'], y_train], axis =1).reset_index(drop = True)
# Model yang akan dievaluasi
models = {
"Naive Bayes": MultinomialNB(),
"Logistic Regression": LogisticRegression(),
"Random Forest": RandomForestClassifier(),
"XGBoost": XGBClassifier(use_label_encoder=False, eval_metric='logloss')
}
# Metrik
scoring = {'accuracy': make_scorer(accuracy_score),
'precision': make_scorer(precision_score),
'recall': make_scorer(recall_score),
'f1': make_scorer(f1_score)}
# Vektorisasi
vectorizers = {
"BoW": CountVectorizer(),
"TF-IDF": TfidfVectorizer()
}
results = []
for vect_name, vectorizer in vectorizers.items():
X = vectorizer.fit_transform(train_data)
for model_name, model in models.items():
vect_mod_name = vect_name +'_'+model_name
# Cross-Validate model
RUN_NAME = f"run_{vect_mod_name}"
mlflow.end_run()
with mlflow.start_run(experiment_id=experiment_id, run_name=RUN_NAME) as run:
# Retrieve run id
RUN_ID = run.info.run_id
cv_results = cross_validate(model, X, train_labels, scoring=['accuracy', 'precision', 'recall', 'f1'], cv=3, return_train_score=False)
for i in range(3):
iteration_result = {
'Iteration': i + 1,
'Model': model_name,
'Vectorizer': vect_name,
'Accuracy': cv_results['test_accuracy'][i],
'Precision': cv_results['test_precision'][i],
'Recall': cv_results['test_recall'][i],
'F1 Score': cv_results['test_f1'][i]
}
results.append(iteration_result)
# Menghitung rata-rata metrik
mean_result = {
'Iteration': 'Mean',
'Model': model_name,
'Vectorizer': vect_name,
'Accuracy': np.mean(cv_results['test_accuracy']),
'Precision': np.mean(cv_results['test_precision']),
'Recall': np.mean(cv_results['test_recall']),
'F1 Score': np.mean(cv_results['test_f1'])
}
results.append(mean_result)
# Lacak metrik
mlflow.log_metric(f"cv_3_{vect_mod_name}_accuracy", mean_result['Accuracy'])
mlflow.log_metric(f"cv_3_{vect_mod_name}_precision", mean_result['Precision'])
mlflow.log_metric(f"cv_3_{vect_mod_name}_recall", mean_result['Recall'])
mlflow.log_metric(f"cv_3_{vect_mod_name}_f1", mean_result['F1 Score'])
# Lacak model
model.fit(X, train_labels)
training_df["ModelOutput"] = model.predict(X)
dataset = mlflow.data.from_pandas(training_df, targets="spam", predictions="ModelOutput", name = f"data_{vect_mod_name}")
mlflow.log_input(dataset, context="training")
if model_name == "XGBoost":
mlflow.xgboost.log_model(model, "model")
else:
mlflow.sklearn.log_model(model, "model")
mlflow.end_run()
return pd.DataFrame(results)Kemudian, kita akan mengeksekusi dan memperoleh hasil evaluasi dengan kode berikut.
email_res = evaluate_models(X_train['email'], y_train, experiment_id)Lihatlah Dashboard MLFlow, dan Anda akan melihat semua run yang telah Anda coba.

Jika Anda memilih salah satu run, Anda dapat melihat informasi yang Anda putuskan untuk dilacak. Misalnya, eksperimen kita mencoba mencatat metrik model eksperimen.

Ada banyak informasi yang bisa Anda lacak dengan MLFlow. Misalnya, hyperparameter, registri model, waktu eksekusi, dll. Anda dapat menyesuaikannya sesuai kebutuhan.
Pada bagian selanjutnya, kita akan memilih salah satu model yang otomatis terdaftar di MLFlow dan menerapkannya.
Pengembangan Model dengan FastAPI dan Docker
Pada bagian ini, kita akan mengembangkan bagian backend di mana model digunakan untuk prediksi. Masih dalam lingkungan lokal, jadi masih banyak keterbatasan. Namun, ini akan menjadi dasar jika Anda ingin memindahkannya ke server cloud.
Semua model telah bekerja dengan baik, karena hanya sedikit yang perlu disesuaikan. Jika kita ingin melihat visualisasi hasil evaluasi, saya akan membuat fungsi untuk melakukannya.
def viz_result_metric(data):
plt.figure(figsize=(15, 8))
metrics = ['Accuracy', 'Precision', 'Recall', 'F1 Score']
for i, metric in enumerate(metrics, 1):
plt.subplot(2, 2, i)
sns.lineplot(data=data, x='Iteration', y=metric, hue='Model', style='Vectorizer', markers=True)
plt.title(f'Model Performance: {metric}')
plt.xlabel('Iteration')
plt.ylabel(metric)
plt.legend(title='Models / Vectorizer', bbox_to_anchor=(1.05, 1), loc='upper left')
plt.tight_layout()
plt.show()Dengan menggunakan fungsi di atas, kita dapat melihat hasil metrik keseluruhan.
# Visualisasikan iterasi data tetapi kecualikan Metrik Mean
viz_result_metric( email_res[email_res['Iteration'] != 'Mean'])
Setiap model menunjukkan perbedaan kecil di antara metrik. Namun, karena kebutuhan bisnis terkait dengan email spam, saya ingin memprioritaskan metrik Precision. Precision mempertimbangkan informasi false positive dalam perhitungannya, dan saya berasumsi bisnis ingin meminimalkan false positive dalam prediksi spamnya. False Positive dalam klasifikasi spam kita berarti email yang diprediksi sebagai spam sebenarnya bukan spam. Kita ingin meminimalkan kasus tersebut karena kita tidak ingin email asli diklasifikasikan sebagai spam.
Itulah mengapa kita akan memilih model Naive Bayes, yang menunjukkan metrik precision terbaik.
Dengan pemilihan model, kita perlu membuat default pipeline untuk model tersebut. Untuk sekarang, saya akan menggunakan kode berikut:
from sklearn.pipeline import Pipeline
from sklearn.feature_extraction.text import CountVectorizer
from sklearn.naive_bayes import MultinomialNB
vectorizer = CountVectorizer()
naive_bayes_classifier = MultinomialNB()
# Membuat pipeline untuk seluruh proses
pipeline = Pipeline([
('vectorizer', vectorizer),
('classifier', naive_bayes_classifier)
])
pipeline.fit(X_train['email'], y_train)Anda juga bisa mendaftarkan model di atas dengan MLFlow. Tapi untuk sekarang, mari buat objek model dengan Pickle.
import pickle
with open('spam_classifier_pipeline.pkl', 'wb') as file:
pickle.dump(pipeline, file)Simpan objek di tempat yang nyaman bagi Anda. Kemudian, kita akan memindahkan pekerjaan kita ke IDE VSCode (atau IDE yang Anda suka).
Backend Klasifikasi Spam
Dari segi struktur, kita akan membuat backend sederhana seperti folder ini.

Untuk menginstal tutorial ini, Anda perlu menginstal Docker Desktop. Jika Anda belum melakukannya, silakan mepelajari dokumentasinya. Setelah Anda menginstal Docker Desktop, kita akan mengatur server dan docker kita.
Pertama, letakkan model pipeline klasifikasi spam di folder aplikasi Anda. Kemudian, buat file Python baru bernama server.py untuk memulai server.
Di server.py, kita akan menggunakan FastAPI untuk membuat API pipeline prediksi.
# isi server.py
import pandas as pd
import numpy as np
import pickle
from fastapi import FastAPI
filename = 'app/spam_classifier_pipeline.pkl'
with open(filename, 'rb') as file:
model = pickle.load(file)
class_names = np.array(['Ham','Spam'])
# Inisialisasi aplikasi sebagai instance kelas FastAPI
app = FastAPI()
@app.get('/')
def read_root():
return {'message': 'Spam Model Classifier API'}
@app.post('/predict')
def predict(data: dict) -> str:
"""
Predicts the class of a given set of features.
Args:
data (dict): A dictionary containing the email to predict.
e.g. {"email": "What is this email?"}
Returns:
dict: A dictionary containing the predicted class.
"""
prediction = model.predict(pd.Series(data['email']))
class_name = class_names[prediction][0]
return class_namePada kode di atas, kita mengatur kelas FastAPI dan alamat untuk root dan prediksi. Prediksi akan menerima data dalam bentuk dictionary dan mengembalikannya dalam bentuk string setelah prediksi selesai.
Untuk memastikan server berjalan dengan baik, kita memerlukan requirements.txt yang berisi semua paket Python yang digunakan untuk server.
pandas
numpy
scikit-learn==1.3.2
uvicorn
fastapiPastikan paket Python yang Anda gunakan untuk model telah sesuai. Catat versi dan paket yang dibutuhkan.
Terakhir, kita harus membuat file docker untuk mengontainerisasi server kita. Tambahkan file docker di folder backend dan masukkan kode berikut.
FROM python:3.11
WORKDIR /code
COPY ./requirements.txt /code/requirements.txt
RUN pip install --no-cache-dir -r /code/requirements.txt
COPY ./app /code/app
EXPOSE 8000
CMD ["uvicorn", "app.server:app", "--host", "0.0.0.0", "--port", "8000", "--reload"]Pada kode di atas, yang terjadi adalah:
Membuat kontainer dari image Python 3.11.
Mengatur direktori kerjanya ke /code.
Menyalin file requirements.txt dan menginstal paket Python yang dibutuhkan.
Menyalin konten direktori app ke dalam direktori /code/app di dalam kontainer.
Menunjukkan bahwa kontainer akan mendengarkan di port 8000.
Ketika kontainer dimulai, akan menjalankan perintah uvicorn app.server:app — host 0.0.0.0 — port 8000 — reload, memulai server Uvicorn dengan aplikasi kita, membuatnya dapat diakses di port 8000, dan mengaktifkan reload otomatis pada perubahan kode.
Saat ini, kita sudah memiliki backend sederhana untuk prediksi. Namun, kita juga membutuhkan frontend untuk berfungsi sebagai UI untuk prediksi spam.
Frontend Klasifikasi Spam
Kita akan menggunakan paket Streamlit sebagai dasar untuk aplikasi frontend. Secara keseluruhan, struktur untuk frontend akan mirip dengan gambar di bawah ini.

Buat file Python dengan nama app.py dan isi dengan kode di bawah ini:
import streamlit as st
import json
import requests
url= "http://backend.docker:8000/predict"
header = {'Content-Type': 'application/json'}
st.set_page_config(page_title="Spam Classifier Front End")
st.title("Welcome to the Spam Classifier Dashboard")
st.write("Enter the Email you want to Predict")
email = st.text_input("Email to predict")
if st.button('Spam Classifier Prediction'):
data = {"email": email}
payload=json.dumps(data)
response = requests.request("POST", url, headers=header, data=payload)
response = response.text
st.write(f"The Email is {str(response)}")Ini adalah dashboard sederhana yang menerima input teks dan tombol untuk mengakses backend kita untuk prediksi. Karena kita hanya membutuhkan paket Streamlit, requirements.txt hanya akan berisi Streamlit.
Buat file Docker tambahan untuk mengontainerisasi frontend kita dengan kode berikut:
FROM python:3.11
WORKDIR /app
COPY ./requirements.txt /app/requirements.txt
RUN pip install --no-cache-dir -r /app/requirements.txt
COPY . /app
EXPOSE 8501
ENTRYPOINT ["streamlit","run"]
CMD ["app.py"]Kode di atas akan menjalankan tindakan berikut:
Membuat kontainer dari image Python 3.11.
Mengatur direktori kerja ke /app.
Menyalin file requirements.txt dan menginstal paket Python yang dibutuhkan.
Menyalin sisa file aplikasi ke dalam kontainer.
Menunjukkan bahwa kontainer akan mendengarkan di port 8501.
Ketika kontainer dimulai, akan menjalankan perintah streamlit run app.py, memulai aplikasi Streamlit dengan app.py sebagai skrip masuk.
Saat semuanya sudah siap, kita akan menerapkan frontend dan backend dengan menggabungkannya menggunakan docker-compose.
Menggabungkan Backend dan Frontend dengan Docker Compose
Kita bisa membangun kontainer Docker secara individual yang berinteraksi satu sama lain, tetapi jauh lebih baik untuk menggabungkannya bersama menggunakan docker-compose karena frontend bergantung pada backend.
docker-compose adalah alat untuk mendefinisikan dan menjalankan aplikasi Docker multi-kontainer. Dengan docker-compose, kita akan menggunakan file YAML untuk mengonfigurasi pengaturan aplikasi kita. Kemudian, kita bisa membuat dan memulai semua layanan dari konfigurasi kita dengan satu perintah.
Sebelum kita mulai, saya membuat folder storage di folder root untuk menjadi penyimpanan persisten untuk semua data dan objek yang kita gunakan dalam proyek ini.
Untuk menggabungkannya, buat file bernama docker-compose.yaml di folder root Anda. Pastikan ada dua folder yang berisi folder backend dan frontend dengan file docker. Di dalamnya, masukkan kode berikut:
version: "3.8"
services:
frontend:
build: spam_frontend
image: spam_frontend:v1.0
ports:
- 8501:8501
networks:
SpamClassifier:
aliases:
- frontend.docker
depends_on:
- backend
volumes:
- ./spam_frontend:/app
- ./storage:/storage
backend:
build: spam_backend
image: spam_backend:v1.0
ports:
- 8000:8000
networks:
SpamClassifier:
aliases:
- backend.docker
volumes:
- ./spam_backend/app:/app
- ./storage:/storage
networks:
SpamClassifier:
driver: bridgePada kode di atas, yang terjadi adalah:
Pembuatan Jaringan:
Sebuah jaringan bernama SpamClassifier dengan driver bridge. Ini memungkinkan kontainer untuk saling berkomunikasi di bawah jaringan ini.
2. Layanan Backend:
Sebuah konteks build ditetapkan untuk backend menggunakan direktori spam_backend.
Docker membangun image bernama spam_backend:v1.0 untuk layanan backend.
Kontainer layanan backend membuka port 8000, yang dipetakan ke port 8000 di host.
Diberikan jaringan alias backend.docker di bawah jaringan SpamClassifier.
Volume dipasang di dua tempat:
1. Direktori ./spam_backend/app pada host sudah terpasang
ke /app dalam kontainer,
memungkinkan perubahan kode tercermin secara real-time.
2. Direktori ./storage pada host dipasang ke /storage
dalam kontainer untuk penyimpanan persisten.Layanan backend dimulai setelah layanan frontend karena kondisi depends_on.
3. Layanan Frontend:
Sebuah konteks build ditetapkan untuk frontend menggunakan direktori spam_frontend.
Docker membangun image bernama spam_frontend:v1.0 untuk layanan frontend.
Kontainer layanan frontend membuka port 8501, yang dipetakan ke port 8501 di host.
Diberikan alias jaringan frontend.docker di bawah jaringan SpamClassifier.
Volume dipasang:
1. Direktori ./spam_frontend pada host dipasang ke /app
di dalam kontainer.
2. Direktori ./storage pada host juga dipasang ke /storage
di dalam kontainer.Tidak ada command eksplisit dalam definisi layanan frontend sehingga akan bergantung pada CMD yang ditentukan dalam Dockerfile di direktori spam_frontend.
Ketika file docker-compose siap, kita akan membangun kontainer dan menjalankannya. Kita perlu menjalankan kode berikut di CLI kita untuk melakukannya.
docker-compose build
docker-compose akan membangun backend dan frontend untuk klasifikasi spam kita. Jika berhasil, kunjungi Docker Desktop dan lihat sesuatu seperti gambar di bawah ini.

docker-compose-nya disebut deploy_model karena folder root saya menggunakan nama itu. Kontainer tidak berjalan, jadi kita perlu memulainya. Anda bisa menjalankannya secara manual, atau kita bisa menggunakan kode berikut.
docker-compose upKemudian, coba kunjungi layanan dashboard frontend Anda. Uji proses prediksi. Jika berhasil, Anda akan melihat seperti gambar di bawah ini.

Anda telah berhasil menerapkan model dan menyajikannya dengan backend server dan frontend.
Pada bagian selanjutnya, kita akan mengatur ulang proses retraining ketika terdeteksi drift dari dataset.
Deteksi Data Drift dan Pemicu Retraining Model
Pada bagian ini, akan ada beberapa komponen yang perlu kita buat. Pada contoh ini, keseluruhan struktur akan terlihat seperti ini:
docker_airflow/
├── config/
├── dags/
├── logs/
├── plugins/
├── .dockerignore
├── .env
├── docker-compose.yaml
└── scripts/
└── project_spam_classifier/
├── dataset/
├── Dockerfile
├── drift_detection.py
├── model_retrain.py
└── requirements.txtUntuk kasus kita, kita akan memasukkan semua kode untuk pemicu dan retraining di bawah folder scripts di folder airflow. Kita akan menggunakan pengaturan Airflow dengan docker untuk mengatur ulang seluruh retraining.
Mari kita mulai dengan mempersiapkan semua skrip terkait. Mulailah dengan deteksi data drift.
Deteksi Data Drift dengan Evidently AI
Pada kasus di dunia nyata, model kita akan selalu berubah. Akan ada perubahan dalam kebutuhan bisnis atau perubahan dalam statistik dataset. Itulah mengapa kita perlu melatih ulang model machine learning secara berkala.
Ada beberapa pemicu untuk model machine learning. Misalnya, penjadwalan reguler, input data baru, deteksi drift, atau perubahan dalam persyaratan model. Dalam kasus kita, kita akan mencoba deteksi data drift dengan Evidently AI.
Evidently AI adalah paket open-source yang memvalidasi model machine learning di produksi. Paket ini berisi API dan dashboard untuk memudahkan pengguna mengontrol apa yang terjadi di produksi. Kita kemudian akan menggunakan salah satu API untuk mendeteksi data drift.
Evidently AI berisi laporan yang sudah dibangun sebelumnya yang melakukan uji statistik untuk mendeteksi data drift. Saya tidak akan menjelaskan lebih lanjut mengenai deteksi ini, tetapi Anda bisa membacanya di dokumentasi mereka. Kita akan menggunakan pengujian dan parameter default untuk melacak semua drift dalam dataset yang ada.
Mari buat file drift_detection.py untuk proses deteksi. Seluruh kodenya bisa dilihat di bawah ini:
from evidently.metrics import TextDescriptorsDriftMetric, ColumnDriftMetric
from evidently.pipeline.column_mapping import ColumnMapping
from evidently.report import Report
import json
import pandas as pd
import os
def check_drift():
# Dapatkan direktori skrip saat ini
script_dir = os.path.dirname(os.path.abspath(__file__))
# Buat path ke folder 'dataset'
dataset_dir = os.path.join(script_dir, 'dataset')
# Buat path lengkap ke file CSV
reference_path = os.path.join(dataset_dir, 'reference.csv')
valid_disturbed_path = os.path.join(dataset_dir, 'valid_disturbed.csv')
# Baca file CSV menggunakan path lengkap
reference = pd.read_csv(reference_path)
valid_disturbed = pd.read_csv(valid_disturbed_path)
# mengatur pemetaan kolom
column_mapping = ColumnMapping()
column_mapping.target = 'spam'
column_mapping.prediction = 'predict_proba'
column_mapping.text_features = ['email']
# list features sehingga text field tidak diperlakukan sebagai fitur biasa
column_mapping.numerical_features = []
column_mapping.categorical_features = []
data_drift_report = Report(
metrics=[
ColumnDriftMetric('spam'),
ColumnDriftMetric('predict_proba'),
TextDescriptorsDriftMetric(column_name='email'),
]
)
data_drift_report.run(reference_data=reference,
current_data=valid_disturbed,
column_mapping=column_mapping)
report_json = json.loads(data_drift_report.json())
dataset_drift_check = report_json['metrics'][2]['result']['dataset_drift']
print(dataset_drift_check)
return dataset_drift_check
if __name__ == "__main__":
check_drift()Pada kode di atas, saya telah membuat referensi dan data “nyata” yang telah berubah secara statistik. Anda bisa menemukan data di folder repositori GitHub di bawah folder dataset.
Pada kode di atas, kita akan membandingkan dataset referensi (data untuk pelatihan model) dan data input. Jika terdapat drift, hasilnya adalah True atau False (Boolean). Hasil ini menjadi titik keputusan apakah kita ingin melatih ulang model kita atau tidak.
Sebagai catatan, kode di atas menggunakan os untuk direktori, karena kita mengasumsikan itu lokal. Jadi, kita membaca data dari dataset lokal. Anda bisa mengubahnya jika Anda menggunakan server cloud atau remote.
Selanjutnya, kita akan mempersiapkan Model Retraining dan lingkungannya.
Skrip Retraining Model
Pada bagian selanjutnya, buat file model_retrain.py dan isi dengan kode di bawah ini:
import pandas as pd
from sklearn.pipeline import Pipeline
from sklearn.feature_extraction.text import CountVectorizer
from sklearn.naive_bayes import MultinomialNB
import pickle
import os
def retrain_model():
file_path = '/opt/airflow/scripts/project_spam_classifier/dataset/training_data.csv'
df = pd.read_csv(file_path)
vectorizer = CountVectorizer()
naive_bayes_classifier = MultinomialNB()
# Buat pipeline untuk seluruh proses
pipeline = Pipeline([
('vectorizer', vectorizer),
('classifier', naive_bayes_classifier)
])
pipeline.fit(df['email'], df['spam'])
output_dir = '/opt/airflow/spam_backend/app'
output_file = 'spam_classifier_pipeline.pkl'
file_path = os.path.join(output_dir, output_file)
# Buat direktori jika belum ada
if not os.path.exists(output_dir):
os.makedirs(output_dir)
# Simpan pipeline jalur yang telah ditentukan
with open(file_path, 'wb') as file:
pickle.dump(pipeline, file)
if __name__ == "__main__":
retrain_model()Pada kode di atas, kita akan membaca dataset pelatihan dari folder yang dimaksud dan menyediakan output di folder lain. /opt/airflow adalah root tempat airflow dieksekusi.
Di folder yang sama, kita juga membuat requirements.txt dengan daftar berikut:
pandas
numpy
scikit-learn==1.3.2
evidentlySelain itu, siapkan file docker sebagai lingkungan untuk menjalankan deteksi drift dan retraining model dengan kode di bawah ini:
# Gunakan runtime Python resmi sebagai parent image
FROM python:3.11
# Atur direktori kerja dalam kontainer
WORKDIR /app
# Salin requirements file ke dalam kontainer di /usr/src/app
COPY ./requirements.txt /app/requirements.txt
# Instal dependensi apa pun di requirements.txt
RUN pip install --no-cache-dir -r /app/requirements.txtKemudian, kita akan membangun kontainer dari file docker di atas dengan kode berikut di CLI. Pastikan Anda menjalankan kode berikut di folder yang berisi file docker yang dimaksud.
docker build -t drift_detection_env .Setelah image docker berhasil dibuat, kita akan mempersiapkan airflow untuk pengaturan ulang.
Airflow untuk Model Retraining
Pada contoh ini, kita akan membangun Airflow dengan docker-compose yang disediakan oleh Airflow. Anda bisa membaca prosesnya di dokumentasinya, tetapi Anda bisa menggunakan docker-compose.yaml yang saya sediakan di repositori.
Sebelum membangun Airflow, tambahkan file .env yang berisi kode berikut:
AIRFLOW_UID=50000Sebagai tambahan kecil, saya mengedit docker-compose.yaml yang berasal dari Airflow untuk memasang folder tambahan. Anda bisa melihatnya di Baris 77:
- ${AIRFLOW_PROJ_DIR:-.}/scripts:/opt/airflow/scriptsSetelah itu, Anda bisa membangun Airflow dengan perintah ini:
docker-compose buildJika berhasil, kunjungi desktop docker, dan Anda akan melihat sesuatu seperti gambar di bawah ini.

Kunjungi web server dengan memilih port yang diberikan. Secara default, Anda bisa masuk ke webserver Airflow dengan memasukkan airflow di kedua kolom username dan password. Anda selalu bisa mengubahnya di file docker-compose.yaml.
Bagian selanjutnya yang perlu kita siapkan adalah DAG. DAG, atau Directed Acyclic Graph, adalah skrip Python yang berisi tugas yang ingin kita jalankan, dengan hubungan dan ketergantungan mereka.
Di folder dags, kita akan membuat file Python bernama spam_classifier_retraining_DAG.py dengan isi sebagai berikut:
import airflow
from airflow import DAG
from airflow.operators.python_operator import ShortCircuitOperator
from airflow.providers.docker.operators.docker import DockerOperator
from docker.types import Mount
from datetime import datetime, timedelta
default_args = {
'owner': 'cornellius',
'depends_on_past': False,
'start_date': datetime(2024, 1, 1),
'email_on_failure': False,
'email_on_retry': False,
'retries': 1,
'retry_delay': timedelta(minutes=5),
}
def condition_check(ti):
# Ambil hasil pemeriksaan kondisi dari XCom
condition_result = ti.xcom_pull(task_ids='condition_check_drift', key='return_value')
# Ubah hasil dari string menjadi boolean jika perlu
condition_result = condition_result.lower() == 'true'
return condition_result
# tentukan DAG
dag = DAG(
'spam_classifier_monthly_model_retraining',
default_args=default_args,
description='A DAG that checks for data drift monthly and conditionally retrains a model',
schedule_interval='0 0 7 * *', # Pada 00:00 on day-of-month 1.
catchup=False
)
# Tugas untuk memeriksa kondisi menggunakan DockerOperator
drift_check_task = DockerOperator(
task_id='condition_check_drift',
image='drift_detection_env:1.0',
command="python /opt/airflow/scripts/project_spam_classifier/drift_detection.py",
docker_url="unix://var/run/docker.sock",
network_mode="bridge",
do_xcom_push=True,
dag=dag,
mount_tmp_dir=False,
mounts=[Mount(source='deploy_model/docker_airflow/scripts', #ubah ke absolute path,
target='/opt/airflow/scripts',
type='bind')]
)
# ShortCircuitOperator untuk memutuskan apakah akan melanjutkan
retraining_decision = ShortCircuitOperator(
task_id='retraining_decision',
python_callable=condition_check,
provide_context=True,
dag=dag,
)
# Tugas dijalankan jika kondisinya True
model_retrain_task = DockerOperator(
task_id='model_retrain_task',
image='drift_detection_env:1.0',
api_version='auto',
auto_remove=True,
command="python /opt/airflow/scripts/project_spam_classifier/model_retrain.py",
docker_url="unix://var/run/docker.sock",
network_mode="bridge",
dag=dag,
mount_tmp_dir=False,
mounts=[
Mount(source='deploy_model/storage', #ubah ke absolute path,
target='/opt/airflow/storage',
type='bind'),
Mount(source='docker_airflow/scripts', #ubah ke absolute path,
target='/opt/airflow/scripts',
type='bind')
]
)
# Atur dependensi tugas
drift_check_task >> retraining_decision >> model_retrain_taskSecara ringkas, yang terjadi dalam DAG kita adalah sebagai berikut:
Membuat kontainer dari iamge drift_detection_env:1.0.
Image ini adalah kontainer yang dikustomisasi yang telah kita buat sebelumnya dengan lingkungan yang diperlukan untuk skrip deteksi drift dan retraining model klasifikasi spam.
2. Mount volume ke kontainer untuk membuat skrip dan penyimpanan yang diperlukan dapat diakses.
Untuk tugas deteksi drift, volume dipasang untuk membuat skrip deteksi drift dapat diakses di /opt/airflow/scripts.
Untuk tugas retraining model, volume tambahan dipasang untuk skrip retraining dan penyimpanan, dapat diakses di /opt/airflow/scripts dan /opt/airflow/storage.
Sumber Mount harus berupa path absolut untuk alamat lokal. Jadi ubah mereka ke lokal Anda; misalnya C:/Users/deploy_model/storage. Kita menggunakan path absolut untuk implementasi lokal.
3. Menjalankan skrip Python tertentu di dalam kontainer menggunakan perintah.
Untuk deteksi drift: python /opt/airflow/scripts/project_spam_classifier/drift_detection.py
Untuk retraining model (jika drift terdeteksi): python /opt/airflow/scripts/project_spam_classifier/model_retrain.py
4. Push dan pull data antara tugas menggunakan XComs Airflow untuk komunikasi antar-tugas.
Tugas deteksi drift melakukan push hasil pemeriksaan drift (True atau False) ke XComs.
Tugas keputusan menarik (pull) hasil ini dari XComs untuk menentukan apakah akan melanjutkan retraining.
XComs, atau komunikasi silang, adalah fitur di Airflow yang memungkinkan tugas berbagi data satu sama lain.
5. Melaksanakan tugas retraining model secara kondisional berdasarkan hasil tugas deteksi drift.
Keputusan ini dibuat menggunakan ShortCircuitOperator berdasarkan apakah drift data terdeteksi atau tidak.
6. Melatih ulang model dan mengembalikan output ke folder spam_backend.
Kontainer yang digunakan dalam tugas dikonfigurasi untuk secara otomatis menghapus diri mereka setelah eksekusi (setidaknya untuk tugas retraining model). DAG dijadwalkan untuk berjalan pada tengah malam pada hari ke-7 setiap bulan. Pada dasarnya, kita memeriksa drift data setiap bulan.
Jika Airflow berhasil mendeteksi DAG, Anda akan melihat DAG di web server.

Untuk mengujinya, Anda bisa menjalankan DAG secara manual dan melihat apakah berjalan dengan sukses. Jika berjalan dengan baik, Anda akan melihat Tugas Terbaru berwarna hijau dengan angka 3, menunjukkan ada 3 tugas yang berhasil dijalankan.

Periksa folder spam_backend untuk melihat apakah model baru telah diperbarui dengan model terbaru atau tidak. Jika berhasil, Anda seharusnya memiliki model terbaru.
Kesimpulan
Kita telah melalui proyek pengembangan model machine learning sederhana dan menggunakan prinsip MLOps untuk melacak eksperimen, mendeteksi drift data, dan secara otomatis melakukan retraining model.
Sebagian besar konsep didasarkan pada implementasi lokal, jadi beberapa lingkungan kolaborasi masih belum ada. Namun, Anda masih bisa menggunakan konsep ini untuk dipindahkan ke cloud environment.
Comments