4 Fungsi Plotting Pandas yang Harus Anda Ketahui
- Cornellius Yudha Wijaya
- 28 Jan 2024
- 4 menit membaca
Diperbarui: 2 Feb 2024

Pandas adalah package yang powerful bagi data scientists. Ada banyak alasan mengapa kita menggunakan Pandas, misalnya, Data wrangling, Data cleaning, dan Data manipulation.
Meskipun begitu, ada metode yang jarang dibicarakan mengenai Pandas yaitu Data Plotting.
Data Plotting, seperti namanya, adalah proses untuk memplot data ke dalam beberapa grafik atau bagan untuk memvisualisasikan data. Meskipun kita memiliki paket visualisasi yang lebih canggih di luar sana, beberapa metode hanya tersedia dalam API plotting Pandas.
Mari kita lihat beberapa metode yang saya pilih.
1. radviz
RadViz adalah metode untuk memvisualisasikan data N-dimensi ke dalam plot 2D. Masalahnya ketika kita memiliki data lebih dari 3 dimensi (fitur) atau lebih adalah kita tidak dapat memvisualisasikannya, tetapi RadViz bisa melakukannya.
Radviz memungkinkan kita memproyeksikan data N-dimensi ke dalam ruang 2D di mana pengaruh setiap dimensi dapat diinterpretasikan sebagai keseimbangan antara pentingnya semua dimensi. Dalam istilah yang lebih sederhana, itu berarti kita bisa memproyeksikan data multi-dimensi ke dalam ruang 2D dengan cara primitif.
Mari mencoba menggunakan fungsi ini pada contoh dataset.
#RadViz example
import pandas as pd
import seaborn as sns
#To use the pd.plotting.radviz, you need a multidimensional data set with all numerical columns but one as the class column (should be categorical).
mpg = sns.load_dataset('mpg')
pd.plotting.radviz(mpg.drop(['name'], axis =1), 'origin')
Gambar di atas adalah hasil fungsi RadViz, pertanyaannya bagaimana Anda akan menginterpretasikan plot ini?
Jadi, setiap Series dalam Data Frame diwakili sebagai irisan yang terdistribusi dengan rata di sekitar lingkaran. Perhatikan contoh di atas, ada lingkaran dengan label nama Series.
Setiap titik data kemudian diplot pada lingkaran sesuai dengan nilai pada setiap Series.
Series yang sangat berkorelasi pada Data Frame ditempatkan lebih dekat ke unit lingkaran. Pada contoh ini, kita dapat melihat data mobil jepang dan eropa lebih dekat dengan model_year, sedangkan mobil USA lebih dekat dengan displacement. Ini berarti mobil jepang dan eropa kemungkinan besar berkorelasi dengan model_year sedangkan mobil AS dengan displacement.
Jika Anda ingin tahu lebih banyak tentang RadViz, Anda dapat melihat makalahnya di sini.
2. bootstrap_plot
Menurut Pandas, bootstrap plot digunakan untuk memperkirakan ketidakpastian dari sebuah statistik dengan mengandalkan pengambilan sampel acak dengan penggantian.
Sederhananya, digunakan untuk mencoba menentukan ketidakpastian dalam statistik dasar seperti mean dan median dengan pengambilan sampel ulang data dengan penggantian (Anda dapat mengambil sampel data yang sama beberapa kali). Anda dapat membaca lebih lanjut tentang bootstrap di sini.
Fungsi boostrap_plot akan menghasilkan plot yang telah di-bootstrap untuk nilai statistik mean, median, dan mid-range untuk jumlah sampel yang diberikan dari ukuran tertentu. Mari kita coba menggunakan fungsi ini dengan contoh dataset.
Sebagai contoh, saya memiliki dataset mpg dan sudah memiliki informasi mengenai data fitur mpg.
mpg['mpg'].describe()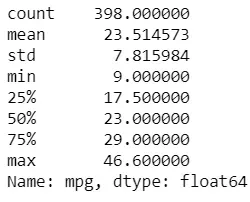
Kita bisa melihat bahwa mean mpg adalah 23,51 dan median adalah 23. Meskipun ini hanya gambaran singkat dari real-world data. Nilai sebenarnya di populasi tidak diketahui, itulah mengapa kita dapat mengukur ketidakpastian dengan metode bootstrap.
#bootstrap_plot example
pd.plotting.bootstrap_plot(mpg['mpg'],size = 50 , samples = 500)
Gambar di atas adalah contoh hasil fungsi bootstap_plot. Perhatikan bahwa hasilnya bisa berbeda dengan contoh sebelumnya karena bergantung pada random resampling.
Kita bisa melihat dalam plot set pertama (baris pertama) adalah hasil pengambilan sampel, di mana sumbu x adalah repetisi, dan sumbu y adalah statistik. Pada set kedua adalah plot distribusi statistik (Mean, Median, dan Midrange).
Ambil contoh mean, sebagian besar hasil berada di sekitar 23, tetapi bisa antara 22,5 dan 25 (kurang lebih). Hal ini menimbulkan ketidakpastian di dunia nyata bahwa rata-rata populasi bisa berkisar antara 22,5 dan 25. Perhatikan bahwa ada cara untuk memperkirakan ketidakpastian dengan mengambil nilai pada posisi quantil 2,5% dan 97,5% (95% confident) meskipun masih tergantung pada penilaian Anda.
3. lag_plot
Lag plot adalah scatter plot untuk time series dan data lagged yang sama. Lag itu sendiri adalah jumlah waktu berlalu yang tetap; misalnya, lag 1 adalah 1 hari (Y1) dengan lag waktu 1 hari (Y1+1 atau Y2).
Lag plot digunakan untuk memeriksa apakah data time series random atau tidak, dan jika data tersebut berkorelasi dengan dirinya sendiri. Random data seharusnya tidak memiliki pola yang dapat diidentifikasi, misalnya linear. Namun, mengapa kita peduli dengan ke-randim-an atau korelasi? Ini karena banyak model Time Series didasarkan pada linear regression, dan salah satu asumsinya adalah tidak ada korelasi (khususnya tidak ada autokorelasi).
Mari kita coba dengan contoh data. Dalam hal ini, saya akan menggunakan package khusus untuk mengambil data saham dari Yahoo Finance yang disebut yahoo_historical.
pip install yahoo_historicalDengan paket ini, kita dapat mengambil riwayat data saham tertentu.
from yahoo_historical import Fetcher
#We would scrap the Apple stock data. I would take the data between 1 January 2007 to 1 January 2017
data = Fetcher("AAPL", [2007,1,1], [2017,1,1])
apple_df = data.getHistorical()
#Set the date as the index
apple_df['Date'] = pd.to_datetime(apple_df['Date'])
apple_df = apple_df.set_index('Date')
Di atas adalah dataset saham Apple dengan tanggal sebagai indeks-nya. Kita bisa mencoba memplot data untuk melihat pola dari waktu ke waktu dengan metode sederhana.
apple_df['Adj Close'].plot()
Kita bisa melihat bahwa Adj Close meningkat dari waktu ke waktu tetapi apakah data itu sendiri menunjukkan pola dengan lag-nya? Kali ini, kita akan menggunakan lag_plot.
#Try lag 1 day
pd.plotting.lag_plot(apple_df['Adj Close'], lag = 1)
Seperti yang dapat kita lihat pada plot di atas, hasilnya hampir mendekati linear. Ini berarti ada korelasi antara Adj Close harian. Ini diprediksi karena harga saham harian tidak akan berubah banyak setiap harinya.
Bagaimana dengan basis mingguan? Mari mencoba memplotnya.
#The data only consist of work days, so one week is 5 days
pd.plotting.lag_plot(apple_df['Adj Close'], lag = 5)
Kita bisa melihat polanya mirip dengan plot lag 1. Bagaimana dengan 365 hari? apakah akan ada perbedaan?
pd.plotting.lag_plot(apple_df['Adj Close'], lag = 365)
Sekarang kita bisa melihat polanya menjadi lebih acak, meskipun pola non-linear masih ada.
4. scatter_matrix
Scatter_matrix seperti namanya; membuat matriks scatter plot. Mari mencoba dengan contoh berikut.
import matplotlib.pyplot as plt
tips = sns.load_dataset('tips')
pd.plotting.scatter_matrix(tips, figsize = (8,8))
plt.show()
Kita bisa melihat bahwa fungsi scatter_matrix secara otomatis mendeteksi fitur numerik dalam Data Frame yang kita lewatkan ke fungsi dan membuat matriks scatter plot.
Pada contoh di atas, antara dua fitur numerik diplot bersama-sama untuk membuat scatter plot (total_bill dan size, total_bill dan tip, serta tip dan size). Sedangkan, bagian diagonal adalah histogram dari fitur numerik.
Ini adalah fungsi sederhana tetapi cukup berguna karena kita bisa mendapatkan banyak informasi dengan satu baris kode.
Kesimpulan
Di sini saya telah menunjukkan 4 fungsi plotting Pandas yang berbeda yang seharusnya Anda ketahui, yaitu:
radviz
bootstrap_plot
lag_plot
scatter_matrix
Semoga bermanfaat!
Artikel ditranslasi oleh: Ahmad Ilham Habibi
Comments